Making your site friendly to search engine crawlers also requires
that you put some thought into your site information architecture. A
well-designed architecture can bring many benefits for both users and
search engines.1. The Importance of a Logical, Category-Based Flow
The search engines face myriad technical challenges in
understanding your site. Crawlers are not able to perceive web pages in
the way that humans do, and thus significant limitations for both
accessibility and indexing exist. A logical and properly constructed
website architecture can help overcome these issues and bring great
benefits in search traffic and usability.
At the core of website organization are two critical principles:
usability, or making a site easy to use; and information architecture,
or crafting a logical, hierarchical structure for content.
One of the very early proponents of information architecture,
Richard Saul Wurman, developed the following definition for
information architect:
information architect. 1) the individual who organizes the
patterns inherent in data, making the complex clear. 2) a person who
creates the structure or map of information which allows others to
find their personal paths to knowledge. 3) the emerging 21st century
professional occupation addressing the needs of the age focused upon
clarity, human understanding, and the science of the organization of
information.
1.1. Usability and search friendliness
Search engines are trying to reproduce the human process of
sorting relevant web pages by quality. If a real human were to do this
job, usability and user experience would surely play a large role in
determining the rankings. Given that search engines are machines and
they don’t have the ability to segregate by this metric quite so
easily, they are forced to employ a variety of alternative, secondary
metrics to assist in the process. The most well known and well
publicized among these is link measurement (see Figure 1), and a
well-organized site is more likely to receive links.
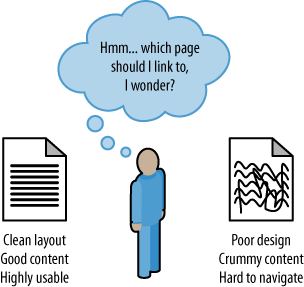
Since Google launched in the late 1990s, search engines have
strived to analyze every facet of the link structure on the Web and
have extraordinary abilities to infer trust, quality, reliability, and
authority via links. If you push back the curtain and examine why
links between websites exist and how they come into place, you can see
that a human being (or several humans, if the organization suffers
from bureaucracy) is almost always responsible for the creation of
links.
The engines hypothesize that high-quality links will point to
high-quality content, and that great content and positive user
experiences will be rewarded with more links than poor user
experiences. In practice, the theory holds up well. Modern search
engines have done a very good job of placing good-quality, usable
sites in top positions for queries.
1.2. An analogy
Look at how a standard filing cabinet is organized. You have the
individual cabinet, drawers in the cabinet, folders within the
drawers, files within the folders, and documents within the files (see
Figure 2).
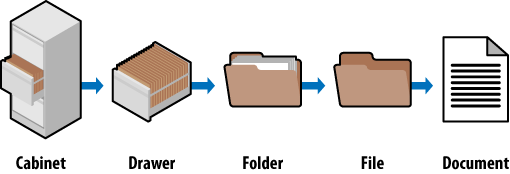
There is only one copy of any individual document, and it is
located in a particular spot. There is a very clear navigation path to
get to it.
If you want to find the January 2008 invoice for a client
(Amalgamated Glove & Spat), you would go to the cabinet, open the
drawer marked Client Accounts, find the Amalgamated Glove & Spat
folder, look for the Invoices file, and then flip through the
documents until you come to the January 2008 invoice (again, there is
only one copy of this; you won’t find it anywhere else).
Figure 3
shows what it looks like when you apply this logic to the popular
website, Craigslist.org.
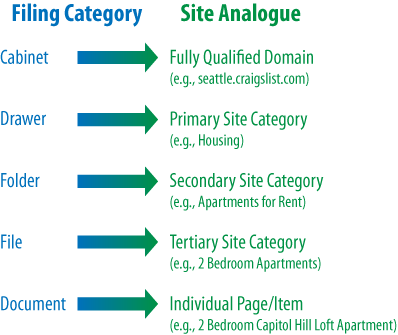
If you’re seeking an apartment on Capitol Hill in Seattle, you’d
navigate to Seattle.Craigslist.org,
choose Housing and then Apartments, narrow that down to two bedrooms,
and pick the two-bedroom loft from the list of available postings.
Craigslist’s simple, logical information architecture has made it easy
to reach the desired post in four clicks, without having to think too
hard at any step about where to go. This principle applies perfectly
to the process of SEO, where good information architecture
dictates:
As few clicks as possible to any given page
One hundred or fewer links per page (so as not to overwhelm
either crawlers or visitors)
A logical, semantic flow of links from home page to
categories to detail pages
Here is a brief look at how this basic filing cabinet approach
can work for some more complex information architecture issues.
1.2.1. Subdomains
You should think of subdomains as completely separate filing
cabinets within one big room. They may share similar architecture,
but they shouldn’t share the same content; and more importantly, if
someone points you to one cabinet to find something, he is
indicating that that cabinet is the authority, not the other
cabinets in the room. Why is this important? It will help you
remember that links (i.e., votes or references) to subdomains may
not pass all, or any, of their authority to other subdomains within
the room (e.g., “*.craigslist.com,” wherein “*” is a variable
subdomain name).
Those cabinets, their contents, and their authority are
isolated from each other and may not be considered to be in concert
with each other. This is why, in most cases, it is best to have one
large, well-organized filing cabinet instead of several that may
prevent users and bots from finding what they want.
1.2.2. Redirects
If you have an organized administrative assistant, he probably
uses 301 redirects inside his literal, metal filing cabinet. If he
finds himself looking for something in the wrong place, he might
place a sticky note in there reminding him of the correct location
the next time he needs to look for that item. Anytime you looked for
something in those cabinets, you could always find it because if you
navigated improperly, you would inevitably find a note pointing you
in the right direction. One copy. One. Only. Ever.
Redirect irrelevant, outdated, or misplaced content to the
proper spot in your filing cabinet and both your users and the
engines will know what qualities and keywords you think it should be
associated with.
1.2.3. URLs
It would be tremendously difficult to find something in a
filing cabinet if every time you
went to look for it, it had a different name, or if that
name resembled “jklhj25br3g452ikbr52k”. Static, keyword-targeted
URLs are best for users and best for bots. They can always be found
in the same place, and they give semantic clues as to the nature of
the content.
These specifics aside, thinking of your site information
architecture in terms of a filing cabinet is a good way to make
sense of best practices. It’ll help keep you focused on a simple,
easily navigated, easily crawled, well-organized structure. It is
also a great way to explain an often complicated set of concepts to
clients and co-workers.
Since search engines rely on links to crawl the Web and
organize its content, the architecture of your site is critical to
optimization. Many websites grow organically and, like poorly
planned filing systems, become complex, illogical structures that
force people (and spiders) looking for something to struggle to find
what they want.